Getting Started With Openccg
OpenCCG is a Java library which can handle both parsing and generation. I’ve mostly used it for surface realization, converting fairly syntactic meaning representations into a natural language text, but you can use it for parsing or for generation from higher-level semantic representations if you’d like.
This tutorial is intended to help you:
- Start exploring OpenCCG with the tccg utility.
If you haven’t installed OpenCCG yet, see the first post on Installing OpenCCG first.
OpenCCG Grammars
OpenCCG uses a grammar to specify how words (1) relate to linguistic structures (2) and carry a particular meaning (3). These grammars also determine which rules can be used to combine linguistic structures and meanings.
The part of the grammar specifying words, their linguistic categories, and their meaning is called a lexicon. The lexicon consists of three part entries, which we might write as follows:
(1) ⊢ (2) : (3)
which means that the string of characters (the ‘word’) in (1) has the linguistic form in (2) and is associated with the meaning in (3).
Let’s consider a simple example with the sentence, “Dogs bark.” We might have a simple grammar with two lexical entries:
Dogs ⊢ NP_x : @x . DOG
bark ⊢ S_e\NP_y : @e . BARK & @e . <SUBJECT> @_y
The first part of each line is just the word itself. After the turnstile character (⊢) we have the syntactic categories, which are also indexed to show how they relate to the meaning of the entry. In the first line NP_x means that the word Dogs has the category “NP”, short for “Noun Phrase” and that this noun phrase carries the meaning associated with the index x. The end of the first line tells us what meaning is ‘at’ the index x. Here our meaning is simply represented by the all-caps DOG, but keep in mind that this is a representation for the abstract meaning of the word (whatever that means).
The next line introduces some extra notation. bark is a verb, which is usually expressed in Combinatory Categorial Grammar (i.e. the ‘CCG’ part of ‘OpenCCG’) by saying that the word bark would be a Sentence S if it combined with an NP on its left. The semantic part of this line introduces the ampersand & used to represent conjunction, which means that this entry’s meaning has multiple parts. The first part @e . BARK just tells us that the sentence S will be associated with a barking event e. The second part tells us who the subject of that barking is: the subject is the meaning of whatever NP the word bark combines with.
When we combine these two words, we can write a new entry:
Dogs bark ⊢ S_e : @e . BARK & @e <SUBJECT> @x & @x . DOG
The precise rules by which these lines, or lexical entries, in the lexicon can combine with each other, along with the exact contents of the structural and the semantic parts of the entries are usually created by human grammar engineers on the basis of linguistic knowledge. For our purposes, we will treat them as a black box which allows us to transform sentences into meanings (going from part (1) to part (3)) or to transform meanings into sentences (going from part (3) to part (1)).
Playing with grammars
Begin by navigating to your openccg/ directory.
You should see a directory named grammars/. Let’s check out the tiny/ grammar in openccg/grammars/tiny/.1
In this directory, you should see a number of XML files. grammar.xml is the parent file, which explains how the other XML files relate to each other. On the commandline, type tccg and hit enter. You should see something like the following:2
Loading grammar from URL: file:OPENCCG_HOME/grammars/tiny/grammar.xml
Grammar 'tiny' loaded.
Enter strings to parse.
Type ':r' to realize selected reading of previous parse.
Type ':h' for help on display options and ':q' to quit.
You can use the tab key for command completion,
Ctrl-P (prev) and Ctrl-N (next) to access the command history,
and emacs-style control keys to edit the line.
where of course OPENCCG_HOME is the location of your openccg/ directory.
As you can see, there are a few options for how to use tccg. For now we want to try out parsing and realizing.
Parsing
Go ahead and enter any string you want at the prompt.
tccg> this is the string i want
Unable to retrieve lexical entries:
Lexicon Exception: this not in lexicon
Uh-oh! One of the words in my string of text (’this’) is not in the lexicon! Damn, we’ll have to try something else. But how can we check what words are in the lexicon so we can avoid this error?
One way is to look at the lexicon.xml file, but that requires understanding the grammar in more detail. If you just want a list of allowed words, try the following sed expression in the same directory (not at the tccg prompt):
$ sed -n 's/.* stem="\(.*\)".*/\1/p' lexicon.xml
pro1
pro2
pro3f
pro3m
pro3n
a
the
some
very
for
buy
rent
buy
rent
Wow! The name of this grammar is no joke! That really is tiny! If you’re not a linguist by training, you might be thrown off by the ‘words’ pro1, pro2, etc. The thing is, our little sed script is actually printing out the word stems available in the grammar, not necessarily their final forms. For example, buy is in the lexicon but not buys, bought, or buying. These forms, if allowed by the rules of the grammar, are generated from the stem. pro1 and pro2 could probably be saved as I and you in the lexicon, but instead the writers of this grammar encoded them in a kind of linguistic notation: pro for ‘pronoun’ and 1, 2, or 3 for ‘first person’, ‘second person’, or ’third person’. There’s also an f, m, or n at the end of the pro3 cases because we have three different forms in the third person singular in English: she, he, and it.3
Okay, so we have a tiny lexicon, but this almost seems… too tiny? Could there be some words we’re missing? There are. So far we’ve only looked at word stems, but the full list of words is given in the morph.xml file. (Now you see why we need a grammar.xml file to combine all these different pieces.)
Running a similar search on the morph file, here is what we find:
$ sed -n 's/.* word="\([A-Za-z]*\)" .*/\1/p' morph.xml
a
I
me
we
us
you
she
her
he
him
it
they
them
book
books
DVD
DVDs
flower
flowers
policeman
policemen
teacher
teachers
buy
buys
buy
bought
rent
rent
rents
rented
Ah, so we’ve got some options then. Let’s jump back into tccg and see what kind of sentences we can parse.
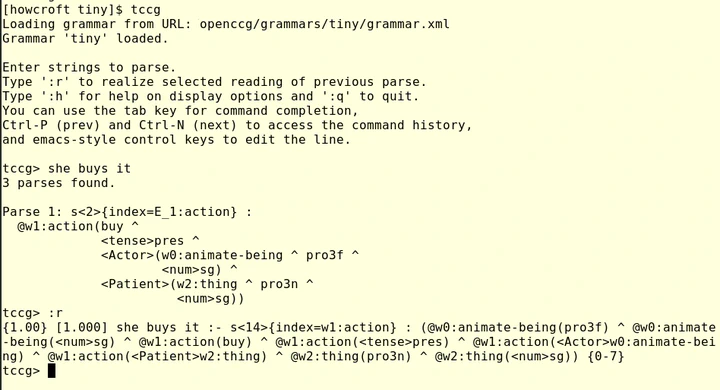
tccg> she buys it
she buys it
3 parses found.
Parse 1: s<2>{index=E_1:action} :
@w1:action(buy ^
<tense>pres ^
<Actor>(w0:animate-being ^ pro3f ^
<num>sg) ^
<Patient>(w2:thing ^ pro3n ^
<num>sg))
By default, tccg tells us (1) how many parses it found and (2) what meaning it found for the best parse.4 For now we won’t worry about this meaning too much—we just want to know how to produce texts based on this meaning. Recall that when we loaded tccg we saw the instruction: Type ':r' to realize selected reading of previous parse.
Let’s try that, immediately after parsing the sentence she buys it.
tccg> she buys it
she buys it
3 parses found.
Parse 1: s<2>{index=E_1:action} :
@w1:action(buy ^
<tense>pres ^
<Actor>(w0:animate-being ^ pro3f ^
<num>sg) ^
<Patient>(w2:thing ^ pro3n ^
<num>sg))
tccg> :r
:r
{1.00} [1.000] she buys it :- s<18>{index=w1:action} : (@w0:animate-being(pro3f) ^ @w0:animate-being(<num>sg) ^ @w1:action(buy) ^ @w1:action(<tense>pres) ^ @w1:action(<Actor>w0:animate-being) ^ @w1:action(<Patient>w2:thing) ^ @w2:thing(pro3n) ^ @w2:thing(<num>sg)) {0-7}
That’s a bit less pretty than before, but you might recognize it as looking similar to our lexical entries above: we have some text on the left, followed by a turnstile-like sequence of characters (:-), followed by a syntactic category (s) associated with an index (w1), followed by a representation for the semantics of the sentence.
Wrapping up
This tutorial got you started using tccg, but there’s still a lot to learn! Try playing around with parsing and realizing (i.e. generating) different sentences based on the tiny grammar and the other grammars provided with OpenCCG.
When you feel comfortable with that, you can explore the different options available under :h in tccg5 or check out the broad coverage grammar derived from CCGbank and documented in openccg/docs/ccgbank-README.
Have fun!
-
Details about all of the grammars provided wtih OpenCCG, along with information about the file formats for these grammars, are provided in the file SAMPLE_GRAMMARS. ↩︎
-
If this doesn’t work, refer to the first tutorial and make sure you have correctly installed OpenCCG and set your environment variables appropriately. ↩︎
-
Of course, the English language has also had the third person singular ’they’ for hundreds of years, but (1) that word won’t necessarily be in every grammar and (2) singular they is still grammatically plural (i.e. takes ‘are’ instead of ‘is’ as the present tense form of the verb ‘be’) even when it’s semantically singular. ↩︎
-
Based on the discussion of the grammar earlier in this tutorial, you might be able to interpret this meaning representation with two additional facts: the colon : is used to indicate what kind of node is ‘at’ some index and the default notation uses ^ instead of & for conjunction. ↩︎
-
OpenCCG has been deployed in real-world systems, but usually by the same researchers actively working on its development. Therefore, the documentation can seem a bit lacking for some of the options listed in tccg’s help menu. If you really want to understand what all of these options mean and how they work, you’ll need to be prepared to read the academic papers on OpenCCG and dig into the codebase yourself. ↩︎